TwinEdge DataOps Workbench
Industrial DataOps and unified namespace for AI-ready operations.
TwinEdge connects OPC UA, MQTT/Sparkplug, historians, databases, files, REST APIs, cloud storage, GIS, and enterprise systems; models them into governed asset, namespace, and canonical graph context; then publishes trusted REST and MCP data products for BI, agents, digital twins, and operational workflows.
Connections
Conditioning
Models
Pipelines
UNS
REST/MCP
TwinEdge makes industrial data useful, physics-aware, AI-governed, and operationally actionable.
Platform in action
Connections, namespace, graph, profiles, and AI workspace in one DataOps surface
DataOps Workbench brings source catalog, tag and topic inspection, industry pack library, standard profile registry, validation endpoints, canonical graph, and AI workspace into one governed context layer.
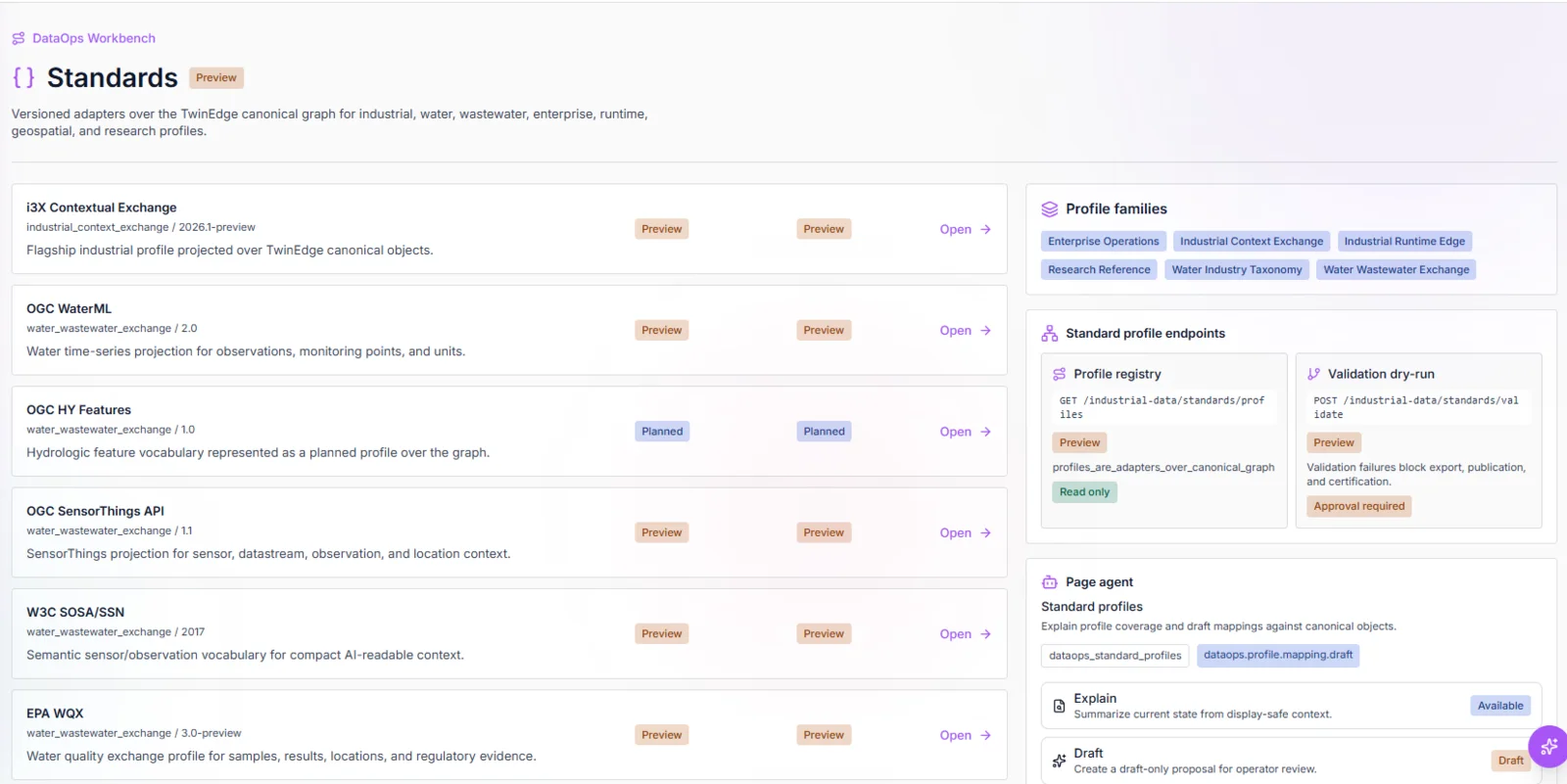
Standards and profile registry
Profile adapters over the canonical graph show visible states such as preview and planned, with validation endpoints and read-only profile registry paths.
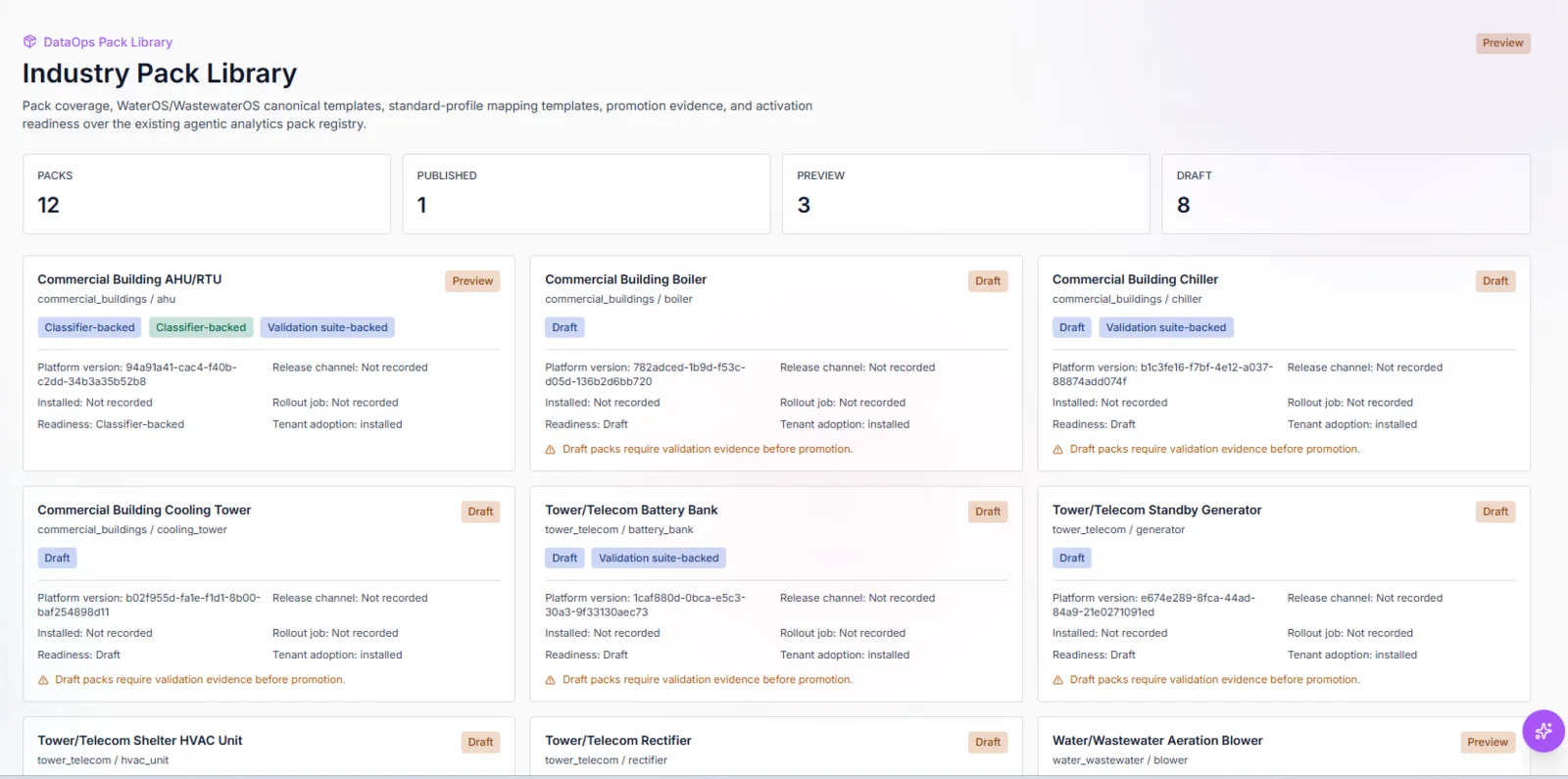
Industry pack library
Industry packs organize WaterOS, WastewaterOS, enterprise, runtime, geospatial, and research profile coverage.
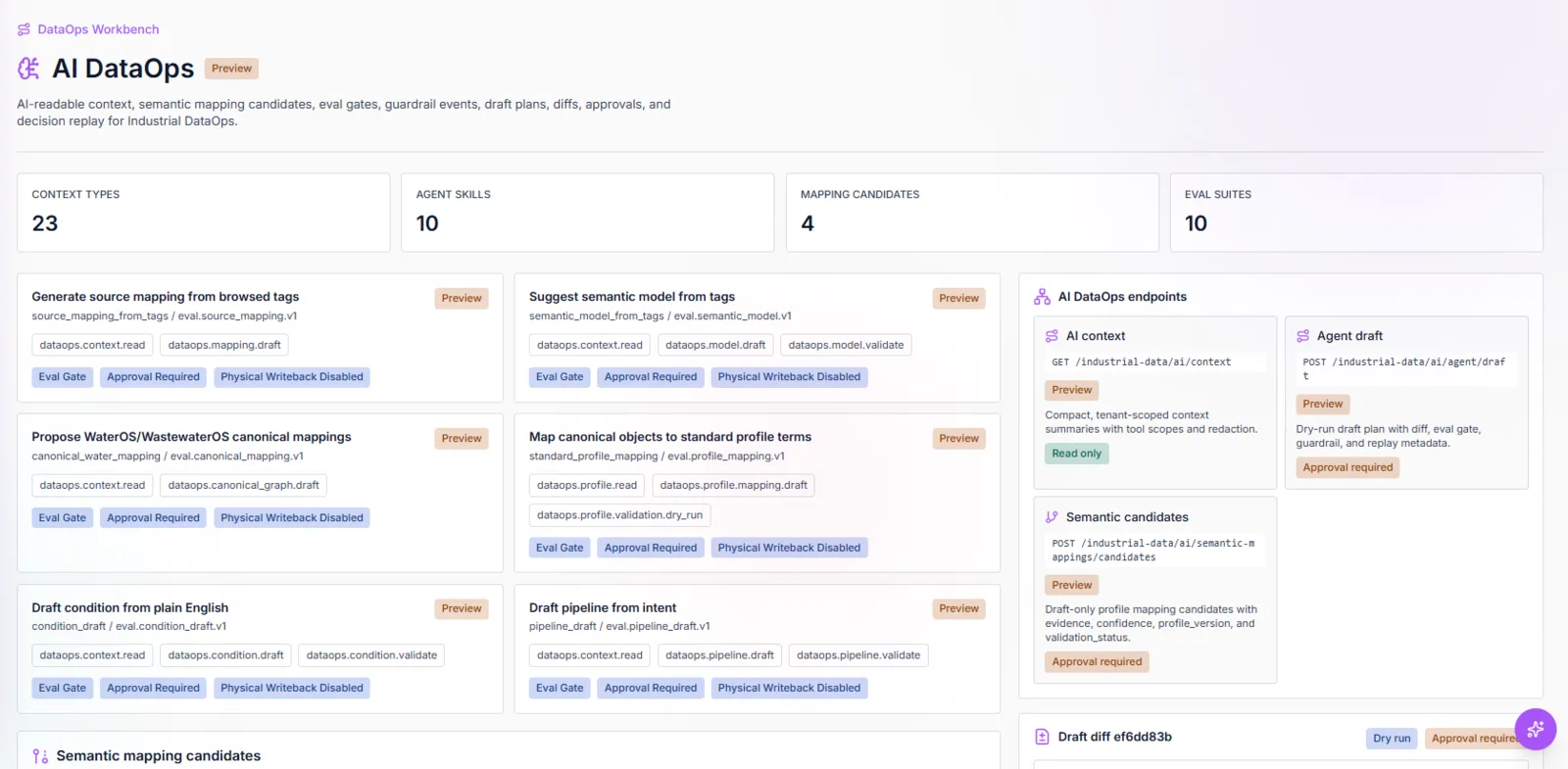
AI DataOps workspace
Agents explain and draft from bounded DataOps context instead of open-ended source-system access.
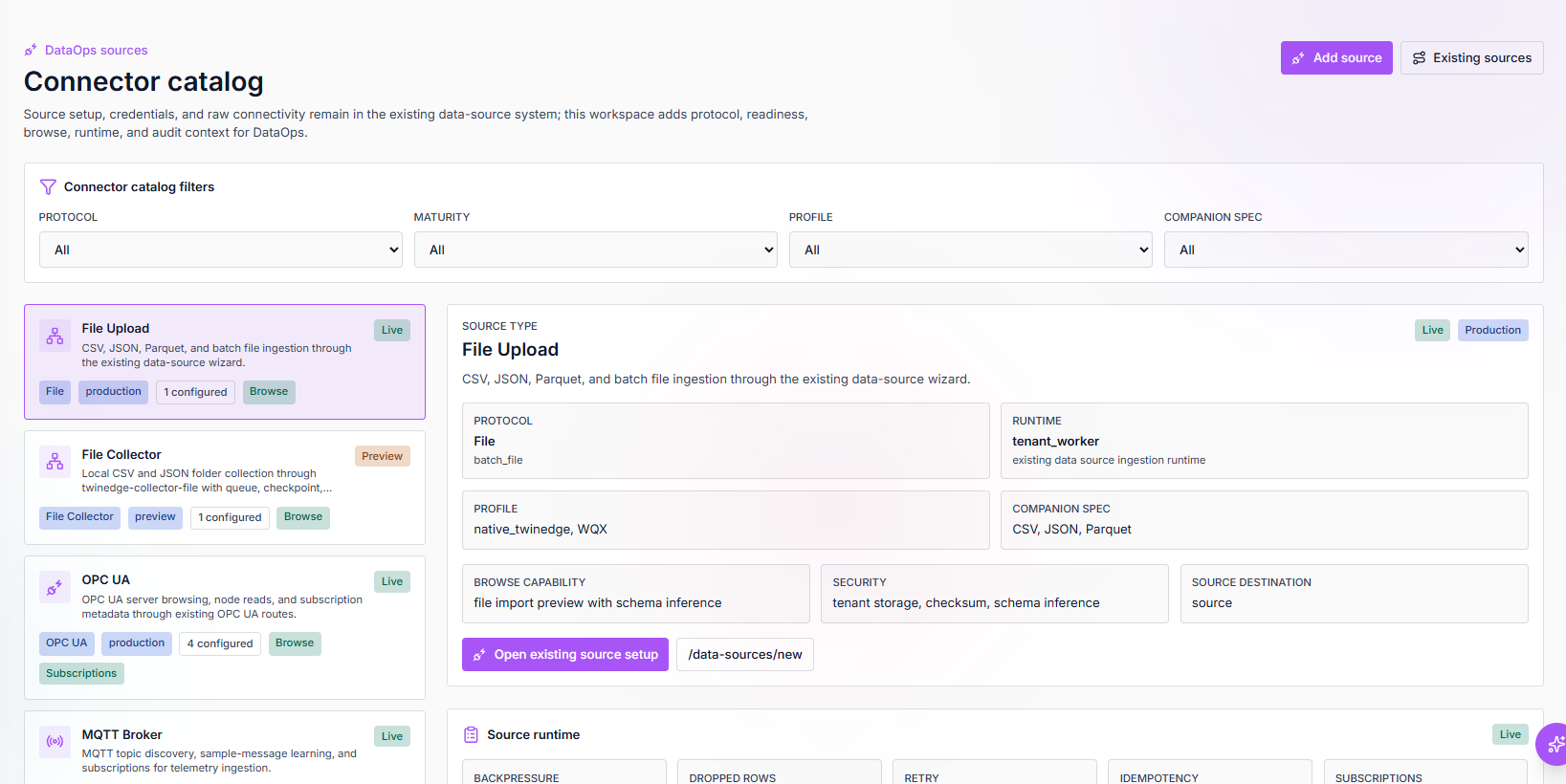
Connector catalog
Source setup, credentials, protocol readiness, browsing, runtime, and audit context stay visible before activation.
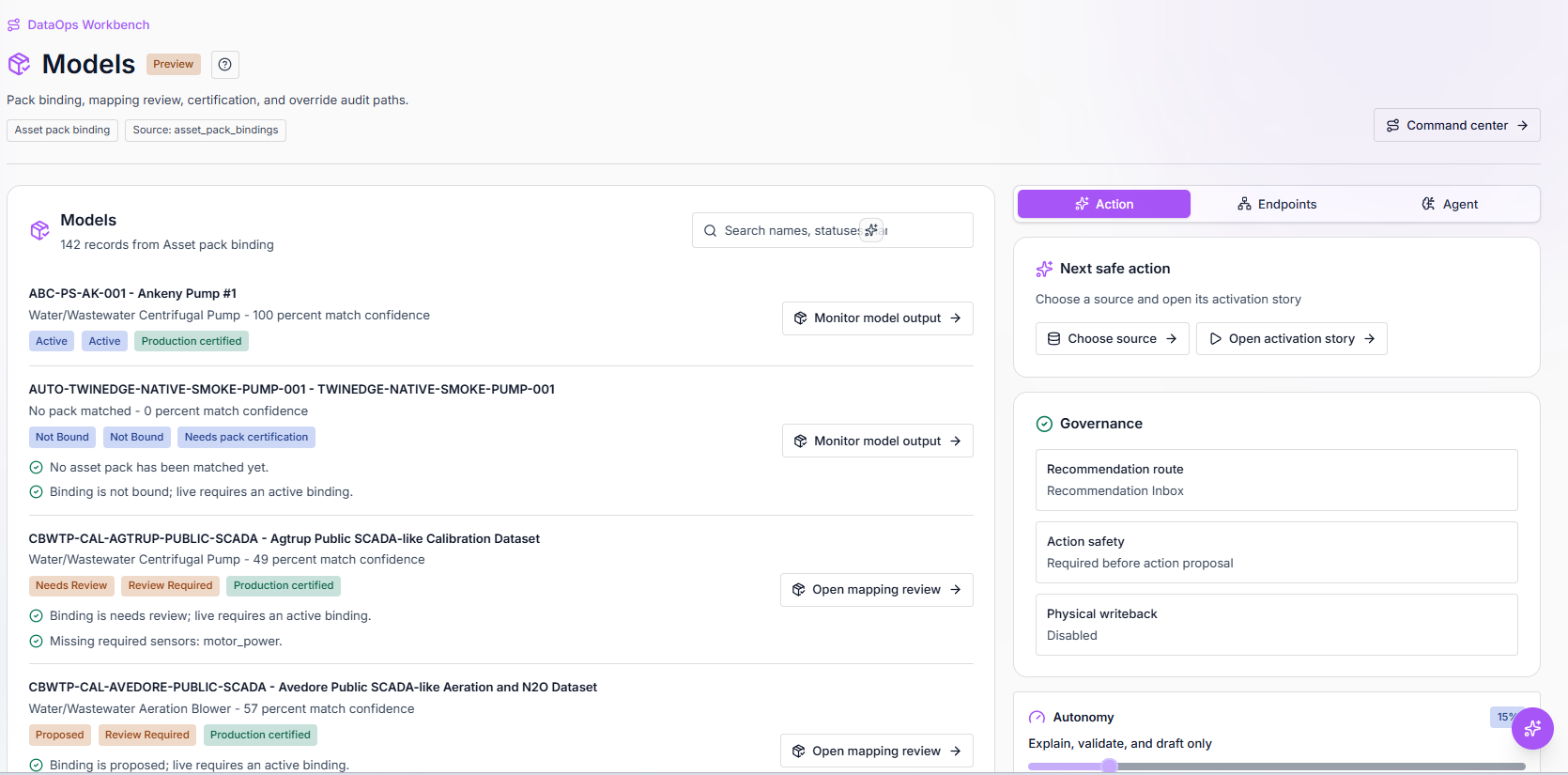
Models and asset binding
Model binding, mapping review, certification state, and safe agent actions connect industrial sources to governed context.
DataOps proof
Make industrial data reusable once, then use it across every product.
TwinEdge DataOps replaces repeated tag mapping and brittle exports with governed asset context that feeds analytics, twins, EAM, Field, BI, APIs, MCP, and industry operating modules.
1
Canonical graph
Shared meaning for assets, signals, work, and evidence.
Many
Source families
OT, IT, GIS, CMMS, LIMS, ERP, files, APIs, and cloud storage.
Reusable
Data products
REST and MCP surfaces expose governed operational context.
Workflow
From industrial source to governed data product
Connect industrial sources, contextualize them into reusable operational models, govern the namespace, and publish trusted data products for teams and AI systems.
Connect and inspect source systems
Register source types, browse tags and topics, inspect payloads and schemas, validate quality, and see what is ready for analytics or publication.
Contextualize and govern the namespace
Map raw data to assets, instances, units, standards, UNS structures, graph relationships, and digital twin inputs so every consumer gets the same meaning.
Publish and operationalize
Expose governed context through cataloged REST APIs, scoped MCP tools, monitoring, approval gates, replayable changes, and downstream operational workflows.
Capabilities
Industrial DataOps capabilities
The workbench covers the core Industrial DataOps buyer checklist, then extends it into TwinEdge twins, agents, EAM, Field, and evidence-backed execution.
Connections and conditioning
Source catalog, tag browser, topic inspection, schema review, unit normalization, quality checks, freshness, transformations, and readiness scoring.
Models, pipelines, and UNS
Reusable asset models, instances, transformations, pipelines, namespace design, canonical graph bindings, profile projections, and operational standards.
REST and MCP publishing
AI-readable data products with catalog entries, schemas, tenant scope, monitor, lineage, approval review, audit trails, and default read-only MCP access.
Where TwinEdge goes further
Industrial DataOps that does not stop at contextualized data.
Standalone DataOps hubs can make plant data cleaner and easier to consume. TwinEdge uses that same governed context as the foundation for physics twins, agents, work execution, field evidence, and operational learning loops.
Physics-aware operational context
Tags, topics, records, and files can bind to asset models, operating envelopes, process twins, failure modes, and physics model inputs.
Governed AI and MCP by default
Published REST and MCP products carry schemas, scope, catalog metadata, approval state, audit history, and replayable source context.
Action loop beyond the data layer
Validated context can flow into Agentic Analytics, AssetOps EAM, Field, GIS-aware response, BI, reports, and evidence-backed work closeout.
Sources, UNS, and profiles
Supported source families, namespace patterns, and standard-profile projections
TwinEdge uses a native canonical graph, supports MQTT/Sparkplug and Unified Namespace patterns, then projects into standard profiles where relevant so teams can keep local operating context and still support exchange patterns.
Engineering controls
Engineering controls for industrial AI.
TwinEdge can show real telemetry, local inference, protocol flows, and agent traces without claiming uncontrolled autonomy or SCADA replacement.
Read-only first
Physical writeback is disabled by default and recommendations pass through approval gates.
Replayable evidence
Plans, diffs, source context, and approval history remain available for review.
Deployment choice
Cloud-connected, local, and offline paths support evaluation without forcing one architecture.
Source system respect
TwinEdge works above SCADA, historians, CMMS, GIS, LIMS, ERP, and data lakes rather than pretending to replace them all.
Outcomes
Why teams choose TwinEdge DataOps
The value is not only contextualized data. TwinEdge carries that context into twins, recommendations, work, field evidence, BI, APIs, and AI systems.
Data teams
Replace ad hoc tag spreadsheets and brittle point-to-point integrations with governed source-to-context workflows.
Plant engineers
Make signal meaning, units, asset identity, and namespace structure explicit so analytics match the real operation.
AI teams
Give agents clean, scoped, replayable operational context instead of raw telemetry dumps or generic API wrappers.
Operations teams
Move validated context into recommendations, work drafts, field tasks, approvals, and evidence-backed closeout.
Connected platform
Extend the same context across the operating layer
DataOps Workbench creates the physics-aware, AI-ready context.
Agentic Analytics uses that context to explain, draft, and validate recommendations.
TwinEdge OS supports cloud-connected, offline, and protocol-rich edge deployments.
AssetOps EAM and TwinEdge Field close the loop from recommendation to work, guided mobile diagnostics, human-reviewed evidence, and closeout.
Water OS, Wastewater OS, Chemical OS, Water Loss OS, Water Quality, Capital Planning, ESG, and Facility OS package industry workflows.
REST and MCP data products make context available to enterprise applications and AI systems.
Frequently asked questions
Questions about TwinEdge DataOps Workbench
Clear answers for buyers, operators, engineers, and evaluation teams.
What is industrial DataOps?
Industrial DataOps is the governed process of connecting OT and IT sources, validating and contextualizing their data, mapping it to reusable asset models, and publishing trusted data products for analytics, twins, applications, and AI agents.
Does DataOps Workbench support a unified namespace?
Yes. Teams can organize MQTT and Sparkplug topics, asset models, canonical graph relationships, standards, and profile projections into a governed namespace rather than exposing raw tag names to every consumer.
Which industrial data sources can TwinEdge connect?
Supported source families include OPC UA, MQTT and Sparkplug, historians, databases, files, REST APIs, cloud storage, GIS, and enterprise systems. Deployment-specific connector support should be confirmed during evaluation.
How does MCP fit into industrial DataOps?
TwinEdge can publish selected operational context through tenant-scoped, audited MCP tools so approved AI clients work from modeled assets and governed data products instead of direct source credentials.
Does TwinEdge replace an industrial historian?
Not necessarily. TwinEdge can work with existing historians and add contextualization, lineage, governed publishing, digital twin inputs, and operational workflows above them.
Who this is not for / non-goals
- •Not a pure point-to-point ETL tool without asset operating context.
- •Not an invitation to expose raw OT credentials to open-ended AI clients.
- •Not a replacement for every enterprise data warehouse or historian investment on day one.
See claims and boundaries and labeled proof.
Related for search and evaluation
Primary product for asset management and maintenance work.
Condition, physics, and remaining-life workflows.
Governed recommendations with approval and replay.
Maximo, HighByte, MaintainX, Fiix, and field alternatives.
Definitions for CMMS, DataOps, UNS, twins, and agents.
Labeled benchmarks and pilot methods.
Evaluate TwinEdge
Plan your first TwinEdge workflow.
Review the operating model with our team, or download TwinEdge to evaluate the platform in your own environment.